作者:Srikanth Manvi
在这篇文章中,我们将讨论如何使用 RAG 技术(检索增强生成)和 Elasticsearch 作为向量数据库来实现问答体验。我们将使用 LlamaIndex 和本地运行的 Mistral LLM。
在开始之前,我们将先了解一些术语。
术语解释:
LlamaIndex 是一个领先的数据框架,用于构建 LLM(大型语言模型)应用程序。LlamaIndex 为构建 RAG(检索增强生成)应用程序的各个阶段提供抽象。像 LlamaIndex 和 LangChain 这样的框架提供了抽象,使得应用程序不会与任何特定 LLM 的 API 紧密耦合。
Elasticsearch 由 Elastic 提供。Elastic 是 Elasticsearch 背后的行业领导者,Elasticsearch 是一个支持全文搜索以实现精确匹配、向量搜索以理解语义和混合搜索以融合两者优势的搜索和分析引擎。Elasticsearch 是一个功能齐全的向量数据库。我们在这篇博客中使用的 Elasticsearch 功能都可在 Elasticsearch 的免费和开放版本中找到。
检索增强生成(RAG)是一种 AI 技术/模式,其中 LLM 通过提供外部知识来生成对用户查询的响应。这使得 LLM 的响应可以针对特定上下文进行定制,响应更为具体。
Mistral 提供开源和优化的企业级 LLM 模型。在这个教程中,我们将使用其开源模型 mistral-7b,该模型可以在你的笔记本电脑上运行。如果你不想在笔记本电脑上运行模型,你也可以选择使用它们的云版本,这种情况下你需要修改本博客中的代码以使用正确的 API 密钥和软件包。
Ollama 帮助在笔记本电脑上本地运行 LLM。我们将使用 Ollama 在本地运行开源的 Mistral-7b 模型。
嵌入(Embeddings)是文本/媒体意义的数值表示。它们是高维信息的低维表示。
我们将要构建什么?
场景:
我们有一个样本数据集(以 JSON 文件形式),其中包含虚构家庭保险公司的客服中心代理和客户之间的对话。我们将构建一个简单的 RAG 应用程序,能够回答诸如此类的问题:
Give me summary of water related issues.
顶层流程
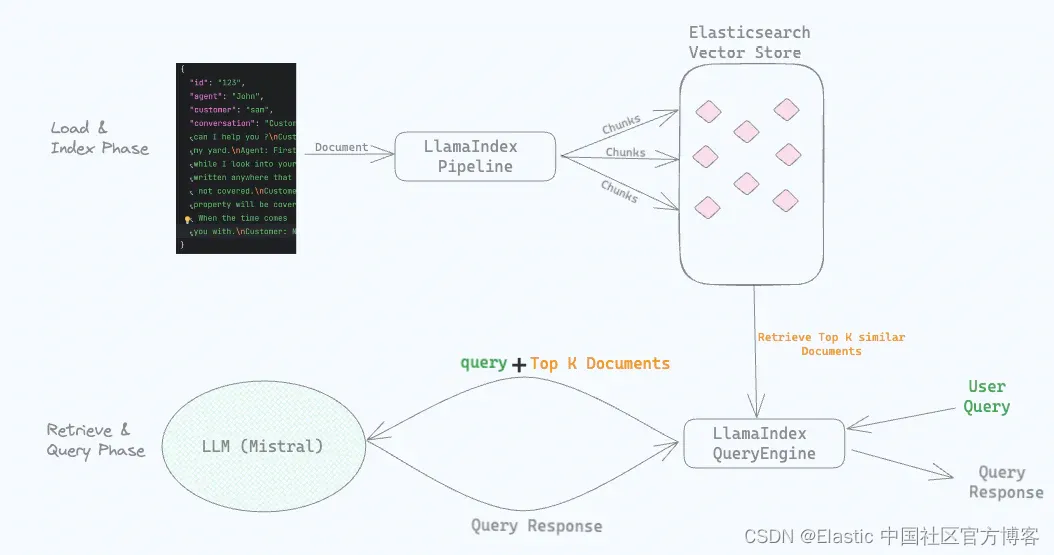
我们有 Mistral LLM 使用 Ollama 在本地运行。
接下来,我们将 JSON 文件中的对话作为文档加载到 ElasticsearchStore(这是由 Elasticsearch 支持的 VectorStore)中。 加载文档时,我们使用本地运行的 Mistral 模型创建嵌入。 我们将这些嵌入与对话一起存储在 LlamaIndex Elasticsearch 矢向量存储 (ElasticsearchStore) 中。
我们配置一个 LlamaIndex IngestionPipeline 并为其提供我们使用的本地 LLM,在本例中 Mistral 通过 Ollama 运行。
当我们提出 “Give me summary of water related issues” 之类的问题时,Elasticsearch 会进行语义搜索并返回与水问题相关的对话。 这些对话与原始问题一起发送到本地运行的 LLM 以生成答案。
构建 RAG 应用程序的步骤:
下载并安装 Ollama。安装 Ollama 后,运行此命令以下载并运行 Mistral:
ollama run mistral第一次下载并在本地运行模型可能需要几分钟的时间。通过询问类似以下问题来验证 Mistral 是否正在运行:“Write a poem about clouds”,然后验证是否喜欢这首诗。确保保持 Ollama 运行,因为我们稍后需要通过代码与 Mistral 模型进行交互。
安装 Elasticsearch
你可以通过创建云部署(具体操作请参见此处指南)或通过 Docker 运行(具体操作请参见此处指南)来启动并运行 Elasticsearch。你也可以从这里开始,创建一个生产级别的自托管 Elasticsearch 部署。
如果你使用的是云部署,请按照指南中的说明获取部署的 API 密钥和云 ID。我们稍后会使用它们。
RAG 应用程序
供参考,整个代码可以在这个 Github 仓库中找到。克隆该仓库是可选的,因为我们将在下面逐步介绍代码。
在你喜爱的集成开发环境(IDE)中,创建一个包含以下 3 个文件的新 Python 应用程序:
-
index.py:用于索引数据的代码。
-
query.py:用于查询和与 LLM 交互的代码。
-
.env:配置属性(如 API 密钥)的文件。
我们需要安装一些包。我们从在应用程序的根目录中创建一个新的 Python 虚拟环境开始。
python3 -m venv .venv激活虚拟环境并安装以下所需的包:
source .venv/bin/activate
pip install llama-index
pip install llama-index-embeddings-ollama
pip install llama-index-llms-ollama
pip install llama-index-vector-stores-elasticsearch
pip install sentence-transformers
pip install python-dotenv配置 Elasticsearch 终端点和 API 密钥。
索引数据
下载 conversations.json 文件,其中包含我们虚构的家庭保险公司的客户和呼叫中心代理之间的对话。 将该文件与 2 个 python 文件以及之前创建的 .env 文件一起放置在应用程序的根目录中。 以下是该文件内容的示例。
{
"conversation_id": 103,
"customer_name": "Sophia Jones",
"agent_name": "Emily Wilson",
"policy_number": "JKL0123",
"conversation": "Customer: Hi, I'm Sophia Jones. My Date of Birth is November 15th, 1985, Address is 303 Cedar St, Miami, FL 33101, and my Policy Number is JKL0123.\nAgent: Hello, Sophia. How may I assist you today?\nCustomer: Hello, Emily. I have a question about my policy.\nCustomer: There's been a break-in at my home, and some valuable items are missing. Are they covered?\nAgent: Let me check your policy for coverage related to theft.\nAgent: Yes, theft of personal belongings is covered under your policy.\nCustomer: That's a relief. I'll need to file a claim for the stolen items.\nAgent: We'll assist you with the claim process, Sophia. Is there anything else I can help you with?\nCustomer: No, that's all for now. Thank you for your assistance, Emily.\nAgent: You're welcome, Sophia. Please feel free to reach out if you have any further questions or concerns.\nCustomer: I will. Have a great day!\nAgent: You too, Sophia. Take care.",
"summary": "A customer inquires about coverage for stolen items after a break-in at home, and the agent confirms that theft of personal belongings is covered under the policy. The agent offers assistance with the claim process, resulting in the customer expressing relief and gratitude."
}在 index.py 中我们定义一个名为 get_documents_from_file 的函数,它读取 JSON 文件并创建一个 Document 列表。Document 对象是 LlamaIndex 处理信息的基本单元。
# index.py
import json, os
from llama_index.core import Document, Settings
from llama_index.core.node_parser import SentenceSplitter
from llama_index.core.ingestion import IngestionPipeline
from llama_index.embeddings.ollama import OllamaEmbedding
from llama_index.vector_stores.elasticsearch import ElasticsearchStore
from dotenv import load_dotenv
def get_documents_from_file(file):
"""Reads a json file and returns list of Documents"""
with open(file=file, mode='rt') as f:
conversations_dict = json.loads(f.read())
# Build Document objects using fields of interest.
documents = [Document(text=item['conversation'],
metadata={"conversation_id": item['conversation_id']})
for
item in conversations_dict]
return documents
创建 IngestionPipeline
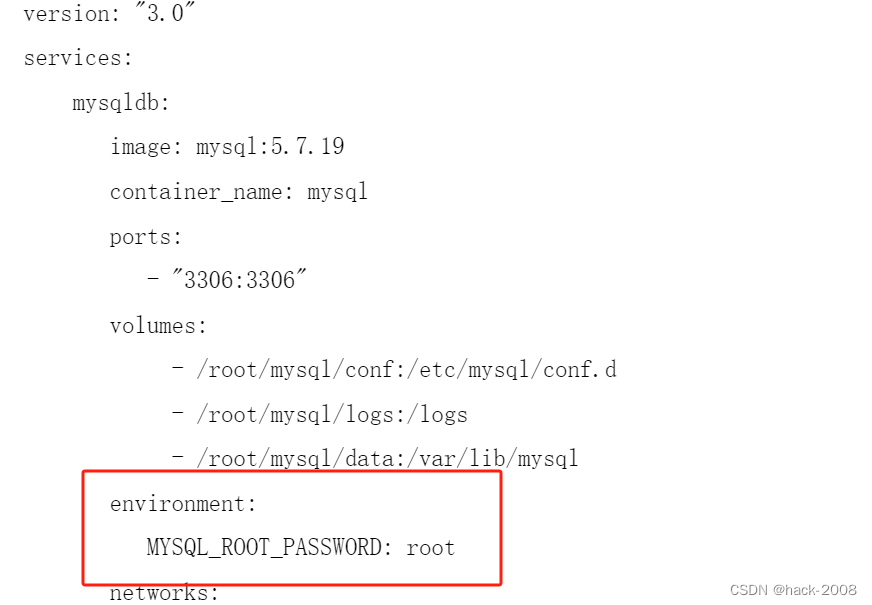
首先,在 .env 文件中添加你在安装 Elasticsearch 部分获取的 Elasticsearch CloudID 和 API 密钥。你的 .env 文件应该如下所示(使用实际值替换):
ELASTIC_CLOUD_ID=<REPLACE WITH YOUR CLOUD ID>
ELASTIC_API_KEY=<REPLACE WITH YOUR API_KEY>LlamaIndex 的 IngestionPipeline 允许你使用多个组件来组成一个管道。在 index.py 文件中添加以下代码:
index.py
# index.py
# Load .env file contents into env
# ELASTIC_CLOUD_ID and ELASTIC_API_KEY are expected to be in the .env file.
load_dotenv('.env')
# ElasticsearchStore is a VectorStore that
# takes care of ES Index and Data management.
es_vector_store = ElasticsearchStore(index_name="calls",
vector_field='conversation_vector',
text_field='conversation',
es_cloud_id=os.getenv("ELASTIC_CLOUD_ID"),
es_api_key=os.getenv("ELASTIC_API_KEY"))
def main():
# Embedding Model to do local embedding using Ollama.
ollama_embedding = OllamaEmbedding("mistral")
# LlamaIndex Pipeline configured to take care of chunking, embedding
# and storing the embeddings in the vector store.
pipeline = IngestionPipeline(
transformations=[
SentenceSplitter(chunk_size=350, chunk_overlap=50),
ollama_embedding,
],
vector_store=es_vector_store
)
# Load data from a json file into a list of LlamaIndex Documents
documents = get_documents_from_file(file="conversations.json")
pipeline.run(documents=documents)
print(".....Done running pipeline.....\n")
if __name__ == "__main__":
main()如前所述,LlamaIndex 的 IngestionPipeline 可以由多个组件组成。我们在以下代码中向管道添加了三个组件:
在这个段落中,我们将讨论使用 SentenceSplitter、OllamaEmbedding 和 ElasticsearchStore 三个关键组件来设置 LlamaIndex 的 IngestionPipeline。以下是这些组件的详细功能和如何结合使用它们:
SentenceSplitter
在 get_documents_from_file() 函数中定义的每个 Document 对象都有一个包含 JSON 文件中对话的文本字段。这个文本字段通常是一长段文本。为了使语义搜索能够有效工作,需要将长文本分割成较小的文本块。SentenceSplitter 类帮助我们完成这一任务。在 LlamaIndex 术语中,这些小块称为 Nodes。每个 Node 都有元数据,指向它所属的 Document。此外,你也可以使用 Elasticsearch 的 IngestPipeline 进行分块,如这个博客所示。
OllamaEmbedding
嵌入模型将文本转换成数字(也称为向量)。拥有数字表示使我们能够进行语义搜索,搜索结果匹配词义而不仅仅是文本搜索。我们为 IngestionPipeline 提供 OllamaEmbedding("mistral")。使用 SentenceSplitter 分割的块通过 Ollama 发送到本地运行的 Mistral 模型,Mistral 为这些块创建嵌入。
ElasticsearchStore
LlamaIndex 的 ElasticsearchStore 向量存储支持将创建的嵌入备份到一个 Elasticsearch 索引中。ElasticsearchStore 负责创建和填充指定的 Elasticsearch 索引。在创建 ElasticsearchStore(在此例中引用为 es_vector_store)时,我们提供我们想要创建的 Elasticsearch 索引的名称(本例中为 calls)、我们希望存储嵌入的索引字段(本例中为 conversation_vector)以及我们希望存储文本的字段(本例中为 conversation)。总结来说,根据我们的配置,ElasticsearchStore 在 Elasticsearch 中创建一个新的索引,其中包括 conversation_vector 和 conversation 字段(以及其他自动创建的字段)。
将它们结合在一起,我们通过调用 pipeline.run(documents=documents) 来运行管道。
运行 index.py 脚本来执行摄取管道:
python index.py管道运行完成后,我们应该在 Elasticsearch 中看到一个名为 “calls” 的新索引。 使用开发控制台运行简单的 elasticsearch 查询,你应该能够看到与嵌入一起加载的数据。
查询
llamaIndex VectorStoreIndex 允许你检索相关文档和查询数据。 默认情况下,VectorStoreIndex 将内存中的嵌入存储在 SimpleVectorStore 中。 然而,可以使用外部向量存储(如 ElasticsearchStore)来使嵌入持久化。
打开 query.py 并粘贴以下代码:
query.py
# query.py
from llama_index.core import VectorStoreIndex, QueryBundle, Response, Settings
from llama_index.embeddings.ollama import OllamaEmbedding
from llama_index.llms.ollama import Ollama
from index import es_vector_store
# Local LLM to send user query to
local_llm = Ollama(model="mistral")
Settings.embed_model= OllamaEmbedding("mistral")
index = VectorStoreIndex.from_vector_store(es_vector_store)
query_engine = index.as_query_engine(local_llm, similarity_top_k=10)
query="Give me summary of water related issues"
bundle = QueryBundle(query, embedding=Settings.embed_model.get_query_embedding(query))
result = query_engine.query(bundle)
print(result)我们定义一个本地 LLM (local_llm) 来指向 Ollama 上运行的 Mistral 模型。 接下来,我们从之前创建的 ElasticssearchStore 向量存储中创建一个 VectorStoreIndex(索引),然后从索引中获取查询引擎。 在创建查询引擎时,我们引用应用于响应的本地 LLM,我们还提供 (similarity_top_k=10) 来配置应从向量存储中检索并发送到 LLM 以获得响应的文档数量。
运行 query.py 脚本来执行 RAG 流程:
python query.py我们发送查询 “Give me summary of water related issues”(请随意自定义查询),并且随相关文档提供的 LLM 的响应应如下所示。
In the provided context, we see several instances where customers have inquired about coverage for damage related to water. In two cases, flooding caused damage to basements and roof leaks were the issue in another case. The agents confirmed that both types of water damage are covered under their respective policies. Therefore, water-related issues encompassing flooding and roof leaks are typically covered under home insurance policies.一些注意事项:
这篇博客是关于使用 Elasticsearch 的 RAG 技术的初学者介绍,因此省略了配置能够使你将此起点用于生产环境的功能。在构建用于生产用例的过程中,你需要考虑更复杂的方面,比如能够使用文档级安全性保护你的数据,将数据分块作为 Elasticsearch Ingest pipeline 的一部分,甚至在用于 GenAI/Chat/Q&A 用例的相同数据上运行其他 ML 作业。
你可能还希望考虑从各种外部来源(例如 Azure Blob Storage、Dropbox、Gmail 等)获取数据并创建嵌入,这可以通过 Elastic Connectors 实现。
Elastic 提供了一种全面的企业级解决方案,可以实现上述所有功能,为 GenAI 用例及更多提供支持。
下一步是什么?
- 你可能已经注意到,我们将 10 个相关对话以及用户问题发送给 LLM 以制定答复。 这些对话可能包含 PII(Personal Identifiable Information - 个人身份信息),例如姓名、出生日期、地址等。 在我们的例子中,LLM 是本地的,因此数据泄漏不是问题。 但是,当你想使用在云中运行的 LLM(例如 OpenAI)时,不希望发送包含 PII 信息的文本。 在后续博客中,我们将了解如何在 RAG 流程中发送到外部 LLM 之前完成屏蔽 PII 信息。
- 在这篇文章中,我们使用了本地 LLM,在即将发布的关于在 RAG 中屏蔽 PII 数据的文章中,我们将了解如何轻松地从本地 LLM 切换到公共 LLM。
准备好将 RAG 构建到你的应用程序中了吗? 想要尝试使用向量数据库的不同 LLMs?在 Github 上查看我们的 LangChain、Cohere 等示例 notebooks,并参加即将开始的 Elasticsearch 工程师培训!
原文:RAG (Retrieval Augmented Generation) with LlamaIndex, Elasticsearch and Mistral — Elastic Search Labs